|
Swetha Sirnam
I'm a graduating PhD student at Center for Research in Computer Vision (CRCV), University of Central Florida advised by Prof. Mubarak Shah. Most of my research focuses on self-supervised learning, multi-modal learning, covering MLLMs, Spatial and Temporal Reasoning in VideoLLMs, Visual Preference Alignment, Safety and Bias analysis. Previously, I graduated with Bachelor in Technology (B.Tech) with Honors and MS by research from International Institute of Information Technology, Hyderabad (IIIT-H), where I was advised by Prof. C. V. Jawahar (Center for Visual Information Technology [CVIT], IIIT-H) and Prof. Vineeth N Balasubramanian, IIT-H.
Email /
Scholar /
Twitter /
Github
|

|
Updates
Apr'26: VRR-QA accepted as CVPR 2026 Highlight paper 💥💥
Feb'26: 3 papers (2 First author papers) accepted at CVPR 2026 💥💥
Dec'25: Our Second Workshop on VideoLLMs accepted at CVPR 2026 💥💥
Nov'25: A First author paper "SMPRO" accepted at AAAI 2026 💥
Oct'25: A paper accepted at ICCV 2025, Oral presentation! (Top 0.6% papers)💥💥
Jun'25: Co-oranized Workshop on VideoLLMs at CVPR 2025 💥💥
Jun'25: Area Chair for Workshop on VideoLLMs at CVPR 2025 💥
Mar'25: Organized Challenges on VideoLLMs at CVPR 2025
Sep'24: Third place - Perception Challenge at ECCV 2024
Jul'24: A First author paper "X-Former" accepted at ECCV 2024 💥
May'24: Started summer internship at Amazon, Palo Alto, CA
May'23: Started summer internship at Amazon, Palo Alto, CA
Jul'23: A First author paper "Multi-Sinkhorn Knopp" accepted at ICCV 2023 💥
May'22: Started summer internship at Amazon, Seattle, CA
Jun'21: UDE paper Oral presentation at CVPR L2ID 2021 💥
May'21: A First author paper "UDE" accepted at ICIP 2021
|

|
PhD Applied Scientist Intern
Amazon, Palo Alto, California, USA. May 2024
- Enhanced visual preference alignment for improving general MLLM understanding.
- Proposed Self-Supervised Flexible Multi-Group Preference Alignment framework without relying on any external experts models or human annotators.
- Outperformed state-of-the-art methods using our novel approach, achieving superior results.
|
|
|
PhD Applied Scientist Intern
Amazon, Palo Alto, California, USA. May 2023
- Enhanced the fine-grained visual perception capabilities of MLLMs, outperforming BLIP-2 & Flamingo.
- Performed large-scale multi-modal training with millions of samples.
- Our X-Former achieved state-of-the-art performance on both fine-grained and general tasks, paper accepted at ECCV 2024.
|
|
|
PhD Applied Scientist Intern
Amazon, Seattle, Washington, USA. May 2022
- Developed a detailed video description framework that employs VideoSwin Transformer for long-form videos.
- Proposed to spatio-temporally match each textual concept to a visual concept for fine-grained representation learning.
- Demonstrated improved performance on captioning task with detailed error analysis
|

|
Analyst
Goldman Sachs, Bengaluru, Karnataka, India.
- Worked with Investment Banking Team primarily.
|
|
|
Intern
Goldman Sachs, Bengaluru, Karnataka, India.
- Interned with Investment Banking Team.
|
Featured Research
My current research interest lies in the field of self-supervised learning for video and image understanding, including multi-modal learning.
|
|
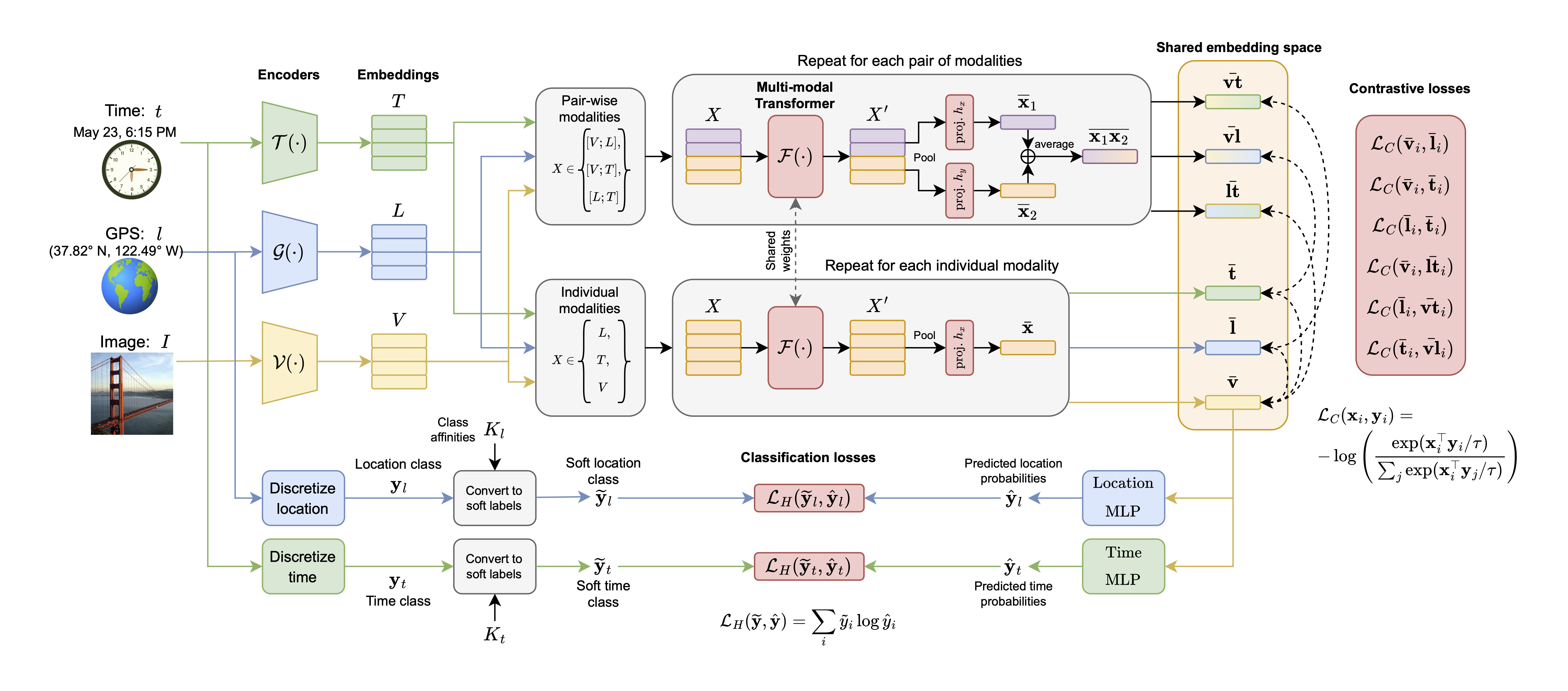
TIGeR: A Unified Framework for Time, Images and Geo-location Retrieval
David G Shatwell,
Sirnam Swetha,
Mubarak Shah
CVPR, 2026
paper /
supp /
arxiv /
project page /
bibtex
|
|
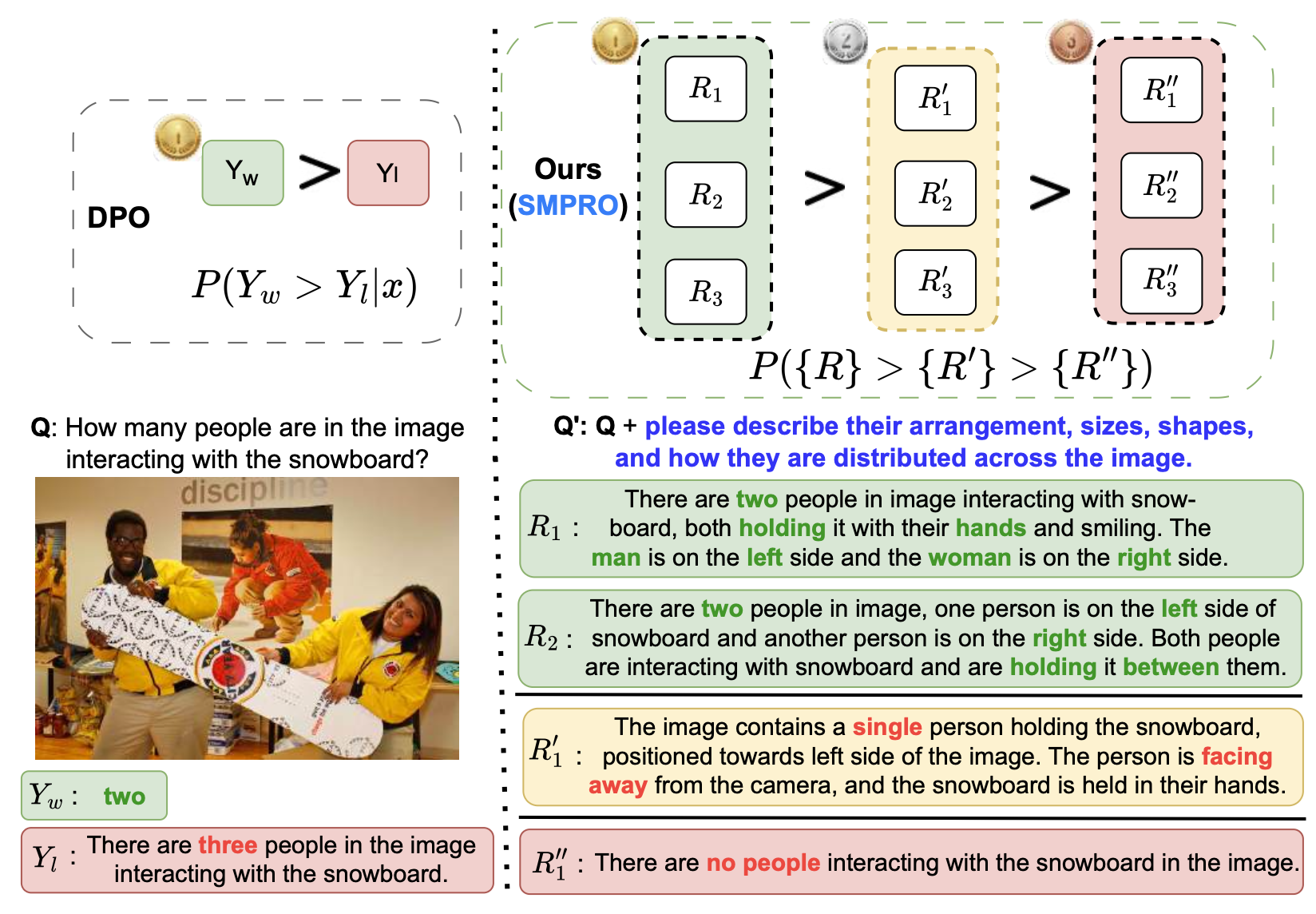
SMPRO: Self-Supervised Visual Preference Alignment via Differentiable Multi-Preference Multi-Group Ranking
Sirnam Swetha,
Rui Meng,
Shwetha Ram,
Tal Neiman,
Son Tran,
Mubarak Shah
AAAI, 2026
paper /
project page /
bibtex
|

|
Safe-LLaVA: A Privacy-Preserving Vision-Language Dataset and Benchmark for Biometric Safety
Younggun Kim*,
Sirnam Swetha*,
Fazil Kagdi,
Mubarak Shah
(*equally contributing first author)
CVPR, 2026
paper /
Data /
arxiv /
code /
project page /
bibtex
|
|
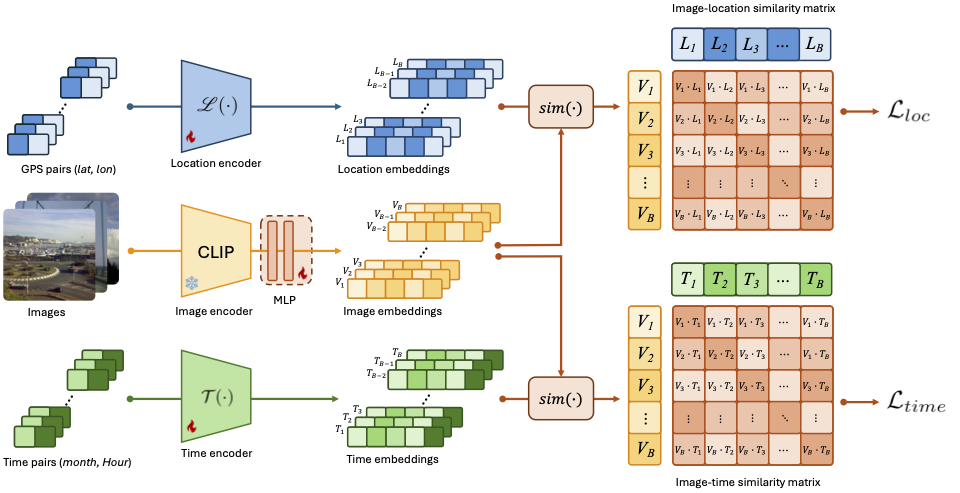
GT-Loc: Unifying When and Where in Images Through a Joint Embedding Space
David G Shatwell,
Ishan Rajendrakumar Dave,
Sirnam Swetha,
Mubarak Shah
ICCV (Oral), 2025
paper /
supp /
arxiv /
code /
project page /
bibtex
|
|
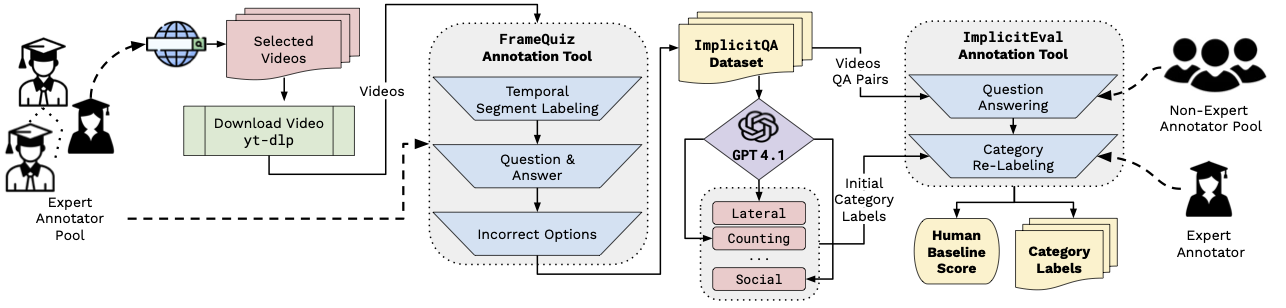
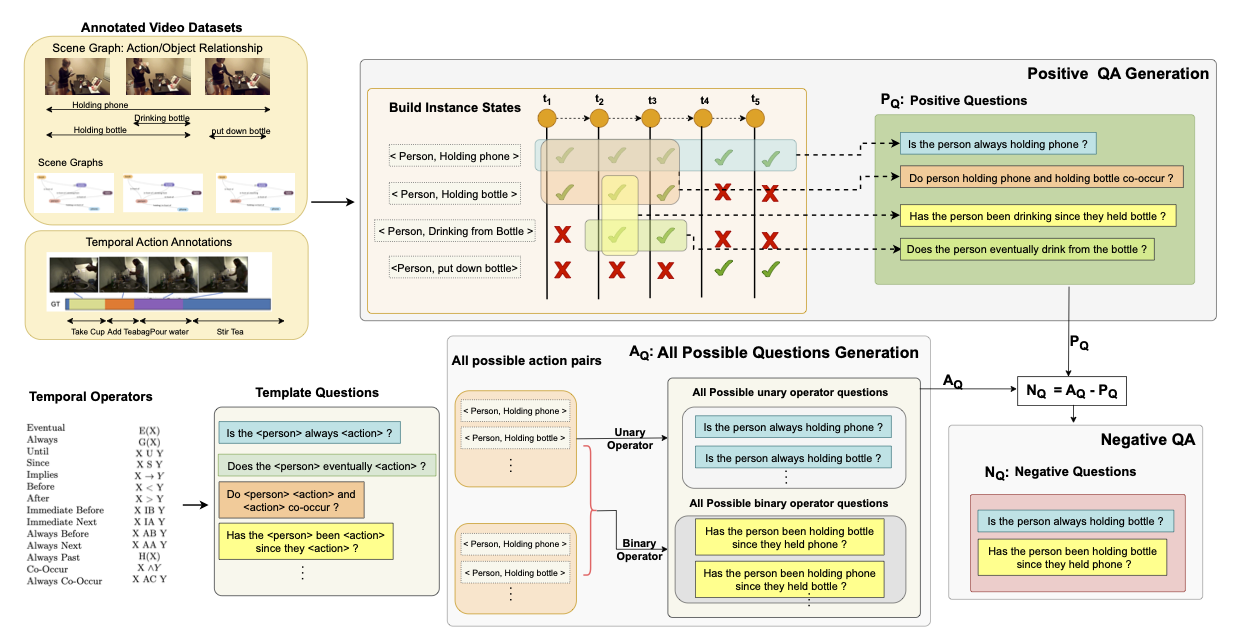
VRR-QA: Visual Relational Reasoning in Videos Beyond Explicit Cues
Sirnam Swetha,
Rohit Gupta,
Parth Parag Kulkarni,
David G Shatwell,
Jeffrey A Chan Santiago,
Nyle Siddiqui,
Joseph Fioresi,
Mubarak Shah
CVPR (Highlight), 2026
paper /
Data /
arxiv /
code /
project page /
bibtex
|
|
TimeLogic: A Temporal Logic Benchmark for Video QA
Sirnam Swetha,
Hilde Kuehne,
Mubarak Shah
arxiv, 2025
paper /
arxiv /
project page /
bibtex
|

|
The Telephone Game: Evaluating Semantic Drift in Unified Models
Sabbir Mollah,
Rohit Gupta*,
Sirnam Swetha*,
Qingyang Liu^,
Ahnaf Munir^,
Mubarak Shah
(*equal contribution)
arxiv, 2025
paper /
Data /
arxiv /
code /
project page /
bibtex
|
|
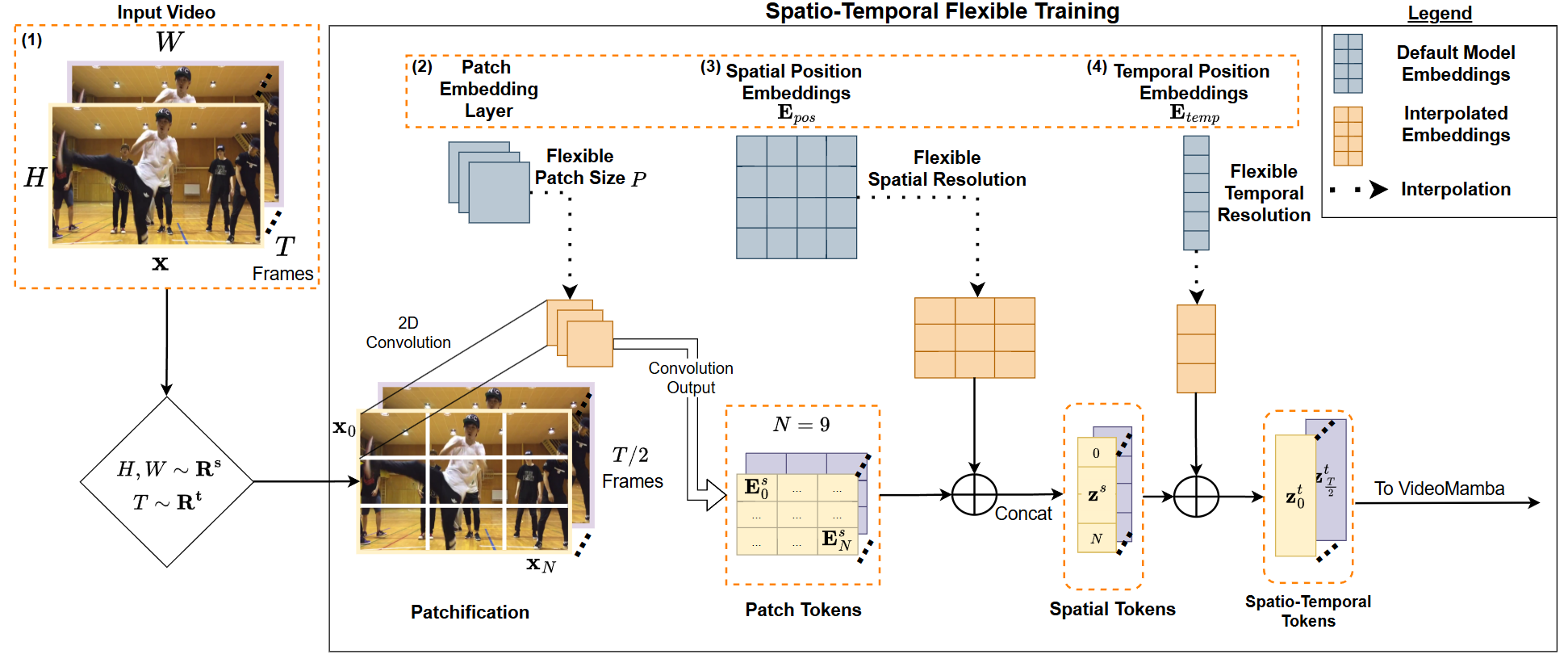
StretchySnake: Flexible SSM Training Unlocks Action Recognition Across Spatio-Temporal Scales
Nyle Siddiqui,
Rohit Gupta,
Sirnam Swetha,
Mubarak Shah
arxiv, 2025
arxiv /
bibtex
|
|
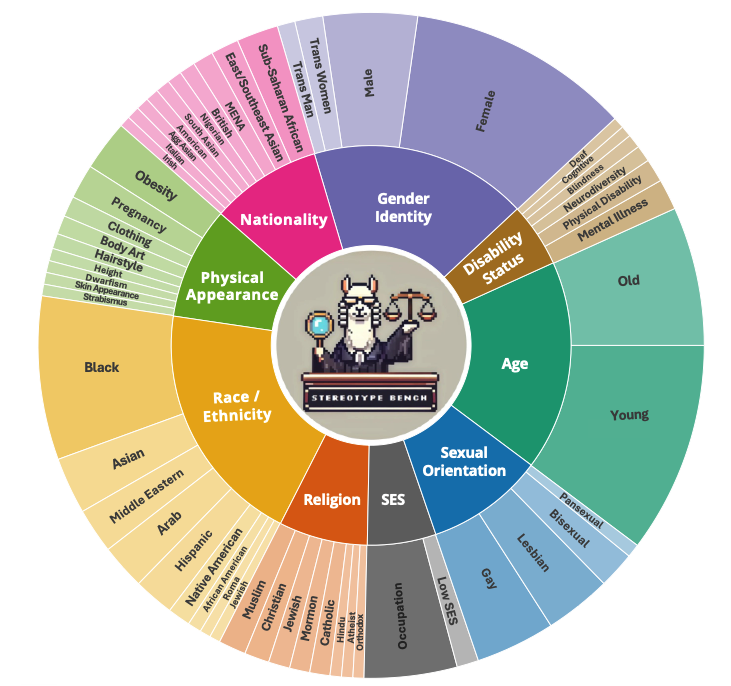
SB-Bench: Stereotype Bias Benchmark for Large Multimodal Models
Vishal Narnaware*,
Ashmal Vayani*,
Rohit Gupta♠,
Sirnam Swetha♠,
Mubarak Shah
(*equally contributing first author, ♠equally contributing second author)
arxiv, 2025
paper /
Data /
arxiv /
code /
project page /
bibtex
|
|
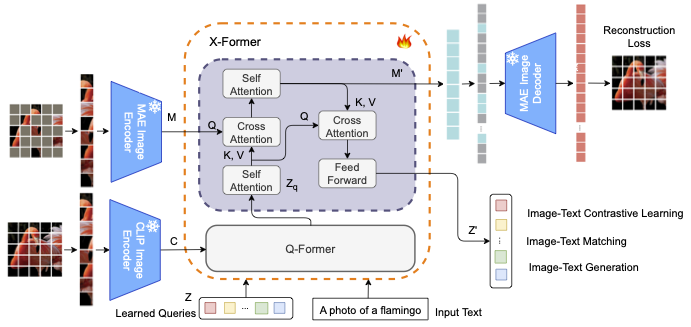
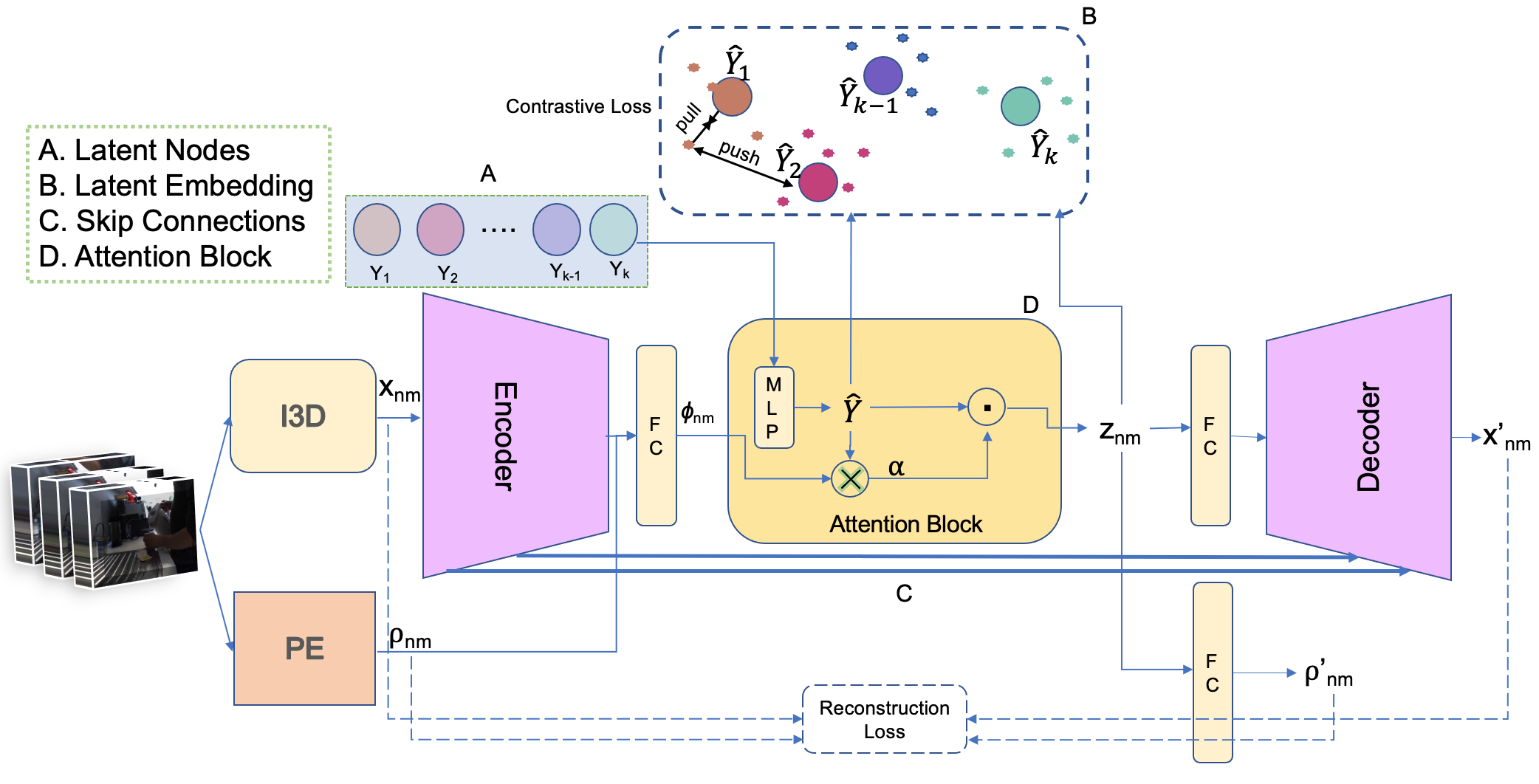
X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
Sirnam Swetha,
Jinyu Yang,
Tal Neiman,
Mamshad Nayeem Rizve,
Son Tran,
Benjamin Yao,
Trishul Chilimbi,
Mubarak Shah
ECCV, 2024
paper /
supplement /
arxiv /
project page /
bibtex
|
|
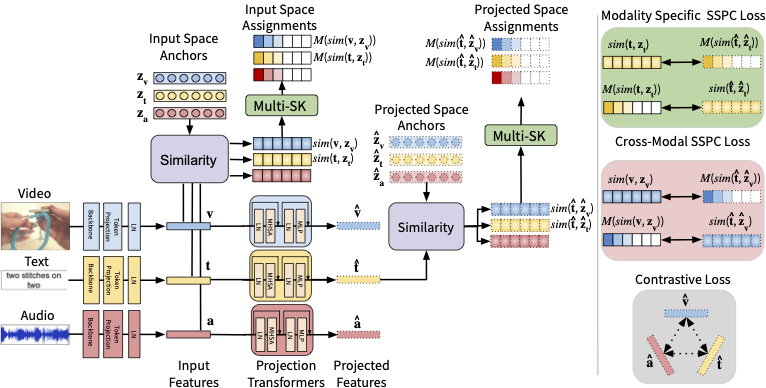
Multi-SK: Preserving Modality Structure Improves Multi-Modal Learning
Sirnam Swetha,
Mamshad Nayeem Rizve,
Nina Shvetsova,
Hilde Kuehne,
Mubarak Shah
ICCV, 2023
paper /
supplement /
arxiv /
code /
project page /
bibtex
|
|
Unsupervised Discriminative Embedding for Action Learning in Complex Activities
Sirnam Swetha,
Hilde Kuehne,
Yogesh S Rawat,
Mubarak Shah
ICIP, CVPR L2ID (Oral), 2021
paper /
arxiv /
project page /
bibtex
|
|
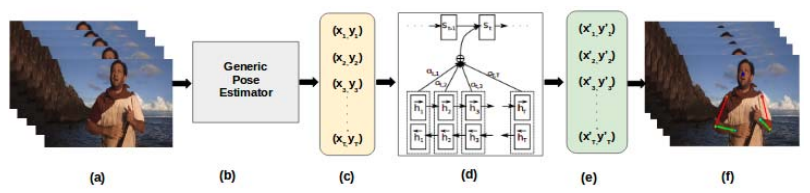
Sequence-to-Sequence Learning for Human Pose Correction in Videos
Sirnam Swetha,
Vineeth N Balasubramanian,
CV Jawahar
ACPR, 2017
paper /
project page /
bibtex
|
|
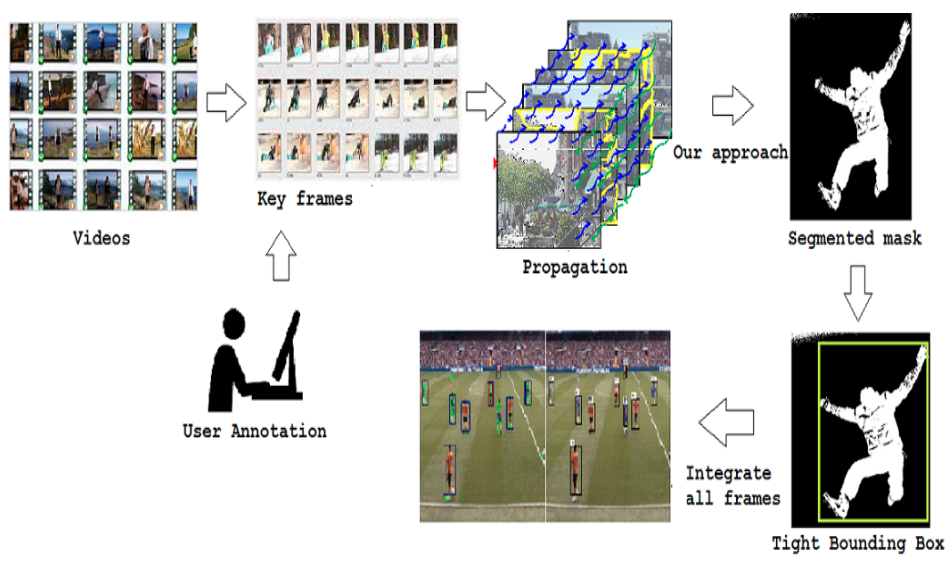
Efficient Object Annotation for Surveillance and Automotive Applications
Sirnam Swetha,
Anand Mishra,
Guruprasad M Hegde,
CV Jawahar
WACVW, 2016
paper /
project page /
bibtex
|

|
Online handwriting recognition using depth sensors
Rajat Aggarwal*,
Sirnam Swetha*,
Anoop M Namboodiri,
Jayanthi Sivaswamy,
CV Jawahar
(*equally contributing first author)
ICDAR, 2015
paper /
project page /
bibtex
|
|